6 RNN 循环神经网络¶
See the definition and introduction on Wikipedia: Recurrent neural network - Wikipedia
6.1 Sequence Modeling¶
基于神经网络的模式识别:
- 模式识别:图像分类、目标检测、图像分割等。
- 序列识别:自动语音识别 ASR、手写文字识别、机器翻译、词性标记等。
如果利用全连接前馈神经网络进行序列建模,或利用卷积神经网络处理时序数据,问题:如何处理未建模序列中不同位置输入的关联?
难点在于序列数据的输入与输出不定长,序列中不同位置的特征不共享。
6.2 RNN¶
前馈神经网络:
- 结构为有向无环图
- 隐含层 \(h = f(\boldsymbol{w}^T \boldsymbol{x})\)
- 适合处理网格化数据
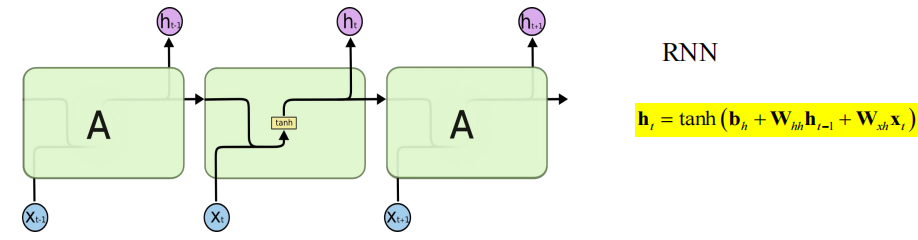
循环神经网络:
- 引入反馈环路
- \(h_t = f(\boldsymbol{w}_x^T \boldsymbol{x}_t + \boldsymbol{w}_h^T h_{t-1})\)
- 适合处理序列化数据
输入词向量的方式:独热编码 one-hot,word2vec,词嵌入 word embedding 等。
RNN 的基本单元:
通过 \(\theta_f,\theta_g\) 实现时序参数共享:
最常见的形式为:
拓展:
双向 RNN(Bidirectional RNN)。
深度循环神经网络:多个 RNN 单元堆叠形成深度循环神经网络(deep RNN),或称为多层 RNN(multi-layers RNN)。
RNN 的优化学习方法:误差沿时间反传 BPTT(Backpropagation through Time)。
Truncated BPTT:实际上我们采用时间截断的 BPTT,误差仅在有限时间内反传。另外,时序数据通常包含多个较短的序列数据。
RNN 容易出现梯度消失和梯度爆炸。对于长序列,计算梯度时(根据链式法则)有多项连乘,要么趋于 0,要么很大,导致梯度消失或梯度爆炸。解决方法:
- 梯度裁剪 gradient clipping:如果梯度超过阈值 \(\boldsymbol{g}_{\text{clipped}}=\theta\dfrac{\boldsymbol{g}}{\|\boldsymbol{g}|} ,\;\text{if } \|\boldsymbol{g}\| > \theta\) ,否则正常梯度更新。
- 换 tanh 激活函数为 ReLU 函数。
- 引入门控机制。
解决梯度消失:
- 更换激活函数
- 使用 Batch Normalization
- 增加残差连接
- 分层预训练
解决梯度爆炸:
- 加正则项
- 分层预训练
- 使用梯度截断
6.3 RNN with Gate¶
问题:在相关信息和预测词之间间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。因此我们需要引入门控机制。
使用门控单元 gate 控制数据流动:
6.3.1 LSTM¶
See the definition and introduction on Wikipedia: Long short-term memory - Wikipedia
关键结构:3个门、2个状态。
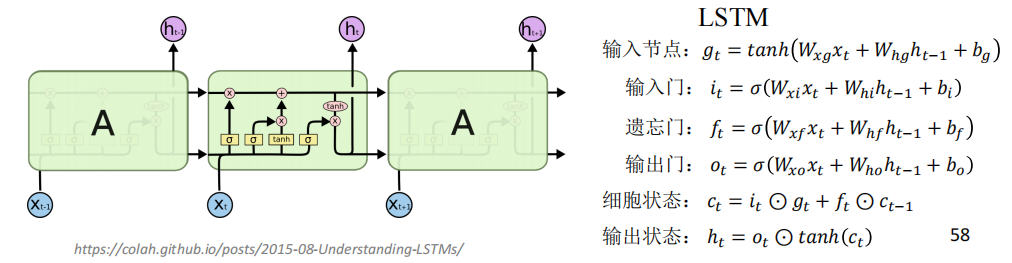
输入节点:\(\boldsymbol{g}_t = \tanh(\boldsymbol{W}_{xg}\boldsymbol{x}_t + \boldsymbol{W}_{hg}\boldsymbol{h}_{t-1} + \boldsymbol{b}_g)\) .
输入门:\(\boldsymbol{i}_t = \sigma(\boldsymbol{W}_{xi}\boldsymbol{x}_t + \boldsymbol{W}_{hi}\boldsymbol{h}_{t-1} + \boldsymbol{b}_i)\) .
遗忘门:\(\boldsymbol{f}_t = \sigma(\boldsymbol{W}_{xf}\boldsymbol{x}_t + \boldsymbol{W}_{hf}\boldsymbol{h}_{t-1} + \boldsymbol{b}_f)\) .
输出门:\(\boldsymbol{o}_t = \sigma(\boldsymbol{W}_{xo}\boldsymbol{x}_t + \boldsymbol{W}_{ho}\boldsymbol{h}_{t-1} + \boldsymbol{b}_o)\) .
细胞状态:\(\boldsymbol{c}_t = \boldsymbol{i}_t \odot \boldsymbol{g}_t + \boldsymbol{f}_t \odot \boldsymbol{c}_{t-1}\) .
输出状态:\(\boldsymbol{h}_t = \boldsymbol{o}_t \odot \tanh(\boldsymbol{c}_t)\) .
运算符 \(\odot\) 表示哈达玛乘积,两个向量逐元素相乘。
单元详解:
遗忘门 forget gate:决定细胞状态 \(\boldsymbol{c}_{t-1}\) 有多少信息将被遗忘。若 \(\boldsymbol{f}_t=1\) 则全部保留,若 \(\boldsymbol{f}_t=0\) 则全部遗忘。
输入门 input gate:决定输入节点 \(\boldsymbol{g}_t\) 有多少信息将被登记。若 \(\boldsymbol{i}_t=1\) 则登记,若 \(\boldsymbol{i}_t=0\) 则丢失。
6.3.2 GRU¶
See the definition and introduction on Wikipedia: Gated recurrent unit - Wikipedia
门控循环单元 GRU (Gated Recurrent Unit)。
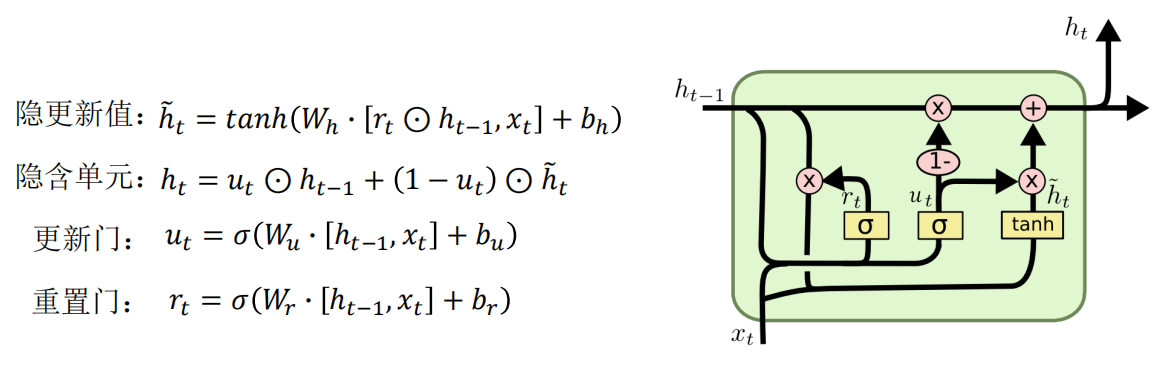
隐更新值:\(\tilde{\boldsymbol{h}}_t = \tanh(\boldsymbol{W}_h \cdot [\boldsymbol{r}_t \odot \boldsymbol{h}_{t-1}, \boldsymbol{x}_t] + \boldsymbol{b}_h)\) .
隐含单元:\(\boldsymbol{h}_t = \boldsymbol{u}_t \odot \boldsymbol{h}_{t-1} + (1 - \boldsymbol{u}_t) \odot \tilde{\boldsymbol{h}}_t\) .
更新门:\(\boldsymbol{u}_t = \sigma(\boldsymbol{W}_u \cdot [\boldsymbol{h}_{t-1}, \boldsymbol{x}_t] + \boldsymbol{b}_u)\) .
重置门:\(\boldsymbol{r}_t = \sigma(\boldsymbol{W}_r \cdot [\boldsymbol{h}_{t-1}, \boldsymbol{x}_t] + \boldsymbol{b}_r)\) .
比较 LSTM 和 GRU:大部分情况下是 LSTM 效果好,但 GRU 参数少。
6.4 Application¶
英文单词生成。
语言模型:
- 准备语料库 corpus,包括训练集和测试集。
- 设计循环神经网络 RNN。
- 确定损失函数,选择优化策略。
- 在训练集上训练学习神经网络参数。
- 在测试集上测试神经网络性能。
One-to-many:图像描述 image captioning,从输入图片生成描述语句。
Many-to-one:情感分析,输入一段文本,输出情感分类。
Many-to-many:机器翻译 machine translation。视频标签 video classification on frame level。