8 图像压缩编码¶
8.1 图像压缩与编码¶
有损编码,无损编码。
为什么图像可以压缩?数据冗余。
- 编码冗余。
- 像素间冗余。
- 心理视觉冗余。
设原始数据个数为 \(n_1\) ,压缩后数据个数为 \(n_2\) ,则压缩率为 \(C_R=\dfrac{n_1}{n_2}\) ,相对数据冗余 \(R_D=1-\dfrac{1}{C_R}\) .
8.1.1 数据冗余¶
自然二进制编码,变长编码。当编码方式使得表达每个像素的平均比特数 \(L_{\text{avg}}\) 没有达到最小值的时候,就有编码冗余。
像素间冗余:
像素间结构或几何上的相关性。为减少图像中像素间冗余,需要将常用的 2D 像素矩阵表达形式,以映射方式转换为频域表达形式,如进行 FFT,DCT 。
心理视觉冗余:
人眼所感受到的图像区域亮度不仅与区域的亮度本身有关,而且与分布相关。人眼并不是对所有视觉信息有相同的敏感度,一些信息在视感觉中与另一些信息相比并不重要,这些并不重要的信息被认为是心理视觉冗余,去除这些信息不会明显降低感受到的图像质量。
心理视觉冗余与人观察图像的方式有关,如:观察图像时,寻找明显的目标特征;不是定量或等同地分析每个像素亮度;对一些高频信息的缺失并不敏感。实例:电视中的隔行扫描。
同一幅图像的心理视觉冗余因人而异。去除心理视觉冗余数据的过程被称为量化。量化是不可逆转操作,会导致部分信息损失,为有损压缩。
8.1.2 图像保真度和质量¶
保真度:描述解码图像相对于原图像的偏离程度。
客观保真度准则:当所损失的信息量可用输入原始图像与编码/解码处理后的输出图像的函数表示时。
- 均方误差准则 \(\text{rms}\) .
- 均方信噪比准则 \(\text{SNR}_\text{ms}\) ,峰值信噪比 \(\text{PSNR}\) .
- 结构相似性 \(\text{SSIM}\) .
主观保真度准则:对一组选择的观察者(>20)展示一幅图像,将他们的评价综合平均,获得一个统计准则。
8.2 典型压缩编码¶
图像压缩标准:
- 静态图像:
- 二值:TIFF, CCITT Group3, CCITT Group4, JBIG, JBIG2.
- 连续色调:TIFF, BMP, GIF, PNG, JPEG, JPEG-LS, JPEG 2000.
- 视频:H.261, H.263, H.265, MPEG-1, MPEG-2, MPEG-4, MPEG-7, MPEG-21, M-JPEG, AVS.
8.2.1 连续色调静止图像压缩标准¶
BMP(Bitmap,位图,无压缩)
- Windows 推出,将像素值逐个记录保存,色彩丰富可达 24 位真彩色,图像储存空间大。
- 面向屏幕显示,所以格式本身与显卡技术的发展相关。
- BMP 文件长度 = BMP 文件头长度 + 调色板字节数 + 像素点阵信息长度。
- BMP 文件中占大头的是像素点阵信息,在不采用压缩的情况下,BMP 的像素点阵信息与图像的像素高度、像素宽度、每像素占用的字节数相关,与图像内容无关。
GIF(Graphics Interchange Format,图像交互格式)
- 1987年推出,一种典型的索引图像,支持动画和透明色,最多可支持 256 色;缺点在于颜色丰富的图像存储开销较大,不善于表现色彩艳丽的画面。
- GIF 颜色虽然少,但却得以进行较大的压缩。
PNG(Portable Network Graphics,便携网络图形)是一种图像文件格式,具有以下特性:
- 1996年推出,是一种较高压缩比的无损图像格式。
- 支持多级颜色透明。
- PNG 的格式有8/24/32三种,称为 PNG 8 / PNG 24 / PNG 32。
- PNG 8 支持两种不同的透明形式,索引透明和 Alpha 透明。
- PNG 24 不支持透明。
- PNG 32 在 24 位基础上增加了 8 位透明通道,因此可展现 256 级透明程度。
PNG 是一种无损压缩位图图形格式,是当前最流行的网络传输格式和图像展示格式。
RVL 压缩算法,是一种专门针对 16bit 单通道深度图像设计的无损压缩算法,微软 Kinect 使用 RVL 压缩算法对采集到的深度图像进行压缩。
| 算法 | 优点 | 缺点 |
|---|---|---|
| PNG | 1. 无损压缩;2. 适用范围广,可以压缩 8bit 单通道、三通道、四通道以及 16bit 单通道图像;3. 通过参数可以调整压缩率;4. 压缩性能较好;5. 普及程度高; | 1. 压缩和解压速度相比于 RVL 算法更慢;2. 实现较 RVL 算法更复杂;3. 运行时资源占用比 RVL 算法多; |
| RVL | 1. 无损压缩;2. 压缩速度快; | 1. 算法专门为 16bit 单通道深度图像设计,适用范围小;2. 压缩率固定无法调节;3. 当图像像素值变化剧烈时,效果较差;4. 普及程度很低;5. 只适合用于实时图像数据传输,不适合用来保存图像; |
JPEG (Joint Picture Expert Group)
- 由 ISO 和 CCITT 联合成立的专家组负责制定静态图像(彩色与灰度图像)的压缩算法。
- 这是一种有损压缩的图像存储技术,文件拓展名为“.jpg”或“.jpeg”。
- 压缩比率通常在 10:1 到 40:1 之间,压缩比越大,品质就越低;反之,越好。
- JPEG 通常基于 DCT 离散余弦变换,目前该方式占绝对主流。
JPEG-LS (Lossless JPEG)
- JPEG-LS 是联合图像小组在1993年添加的针对连续色调图像的基于自适应预测、上下文模型和 Golomb 编码的无损到近无损的压缩标准。
- JPEG-LS 使用 DPCM 预测编码模型来代替 DCT,通过利用图像中已经编码的相邻像素点来预测:使用待预测像素点的三个最相邻的三个像素点(上,左,左上)作为预测参考点,且对预测误差值使用熵编码。
- JPEG-LS 适用于复杂度非常低的低复杂度硬件实现。
JPEG 2000
- 由 ISO 和 CCITT 联合成立的专家组于1997年开始征集提案的,并准备将现有 JPEG 标准进行更新换代的一个新标准。
- JPEG 2000 不仅能提高对图像的压缩质量,尤其是低码率时的压缩质量,还将得到许多增加的功能,包括根据图像质量、视觉感受和分辨率进行渐进传输,对码流的随机存取和处理,开放结构,向下兼容等。
- JPEG 2000 于1999年3月形成工作草案,其中的编码变换采用了小波变换 DWT。
- JPEG 2000 新标准于2000年问世。
- JPEG 2000 与 JPEG 不兼容。
8.2.2 视频压缩标准¶
MPEG 系列标准 (Moving Picture Expert Group)
- ISO/IEC/JTC1/SC29 的一个工作组 WG11,1988年成立,目前有25个国家(团体)的200多个公司300多名成员分10个组工作。
- JPEG 的目标是专门集中于静止图像压缩,MPEG 的目标是针对运动图像的数据压缩,但是 JPEG 和 MPEG 有密切联系。
- MPEG 专家小组,不仅限制于数字视频压缩,音频及音频和视频的同步问题都不能脱离视频压缩独立进行。
中国的视频压缩标准:AVS (Audio Video coding Standard)
连续帧图像压缩的基本思想:
- 帧内编码技术:根据同帧附近像素来加以预测。
- 帧间编码技术:根据附近帧中的像素来加以预测。
MPEG 帧的分类:
- I帧(Intra-picture),不需要参考其它画面而独立进行压缩编码的画面。
- P帧(Predicted-picture),参考前面已编码的 I 或 P 画面进行预测编码的画面。
- B帧(Bidirectional-picture),既参考前面的 I 或 P 画面、又参考后面的 I 或 P 画面进行双向预测编码的画面。
8.2.3 JPEG 压缩技术¶
离散余弦变换 DCT 类似于离散傅里叶变换 DFT,但是只使用实数。在傅立叶级数展开式中,如果被展开的函数是实偶函数,则其傅立叶级数中只包含余弦项,再将其离散化可导出余弦变换。
一维和二维 DCT :
一般情况下,对于同一图像,变换后舍弃部分系数再逆变换,均方误差:DFT > WHT > DCT 。
- DCT 的信息压缩能力比 DFT 和 WHT 的能力要强。
- WHT 沃尔什-哈达玛变换是最容易实现的。
- DCT 在信息压缩能力和计算复杂性之间提供了很好的平衡,因此,许多变换编码系统都是以 DCT 变换为基础的。
- 对比其它方法,DCT 变换具有使用单一的集成电路就可以实现,可以将最多的信息包装在最少的系数之中。
- 可使“分块噪声”的块效应最小,这些分块噪声是由子图像之间的可见边界造成的。
DCT 变换具有很强的“能量集中”特性,是图像压缩中常用的一个变换编码方法。大多数图像,变换后能量大部分集中在少数几个变换系数上,降低了像素间的相关性。
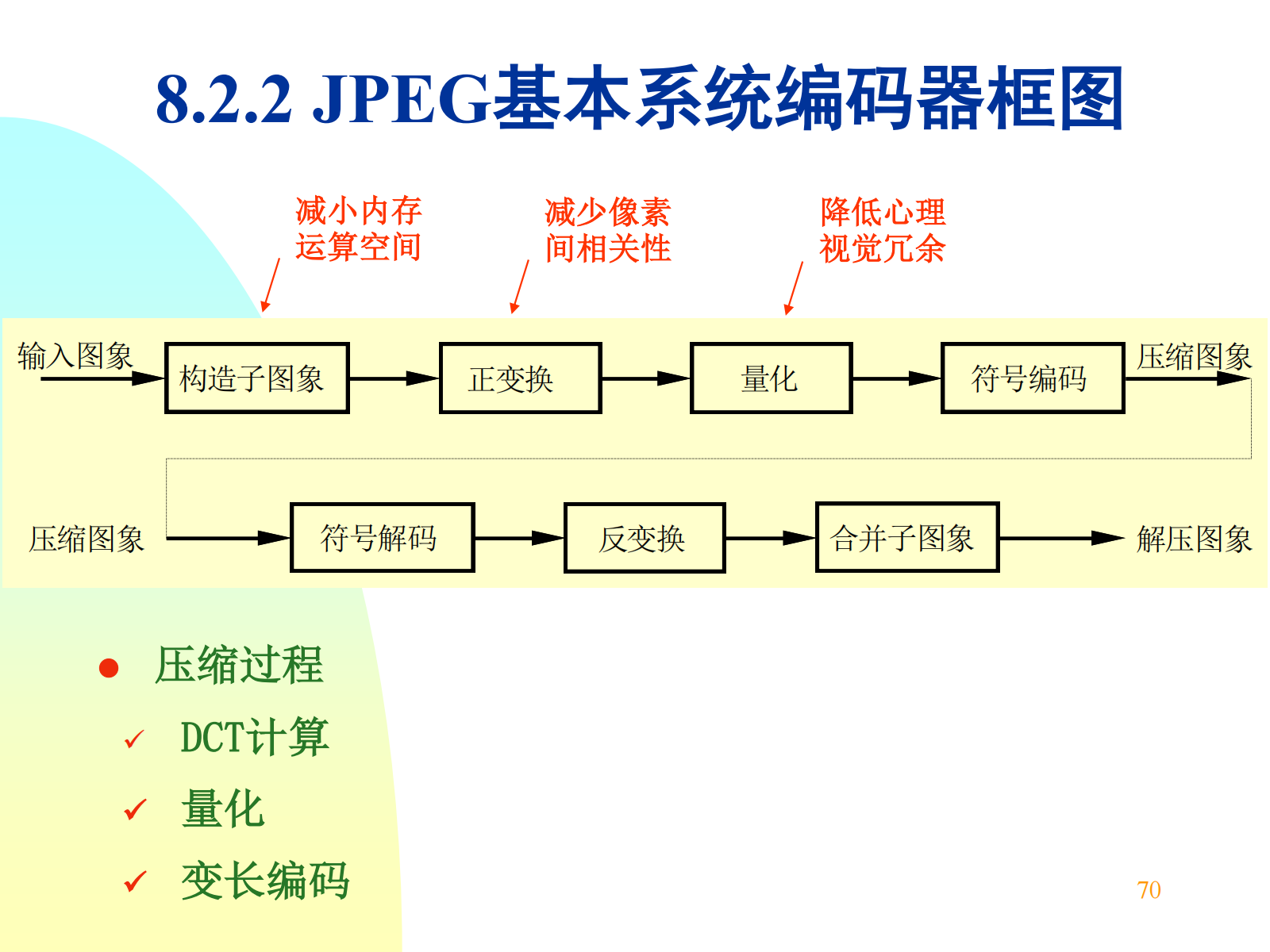
图像分解:减少变换的计算复杂度。通常分解为 8x8 的子图像。
图像变换:解除每个子图像内部像素之间的相关性,将尽可能多的信息集中到尽可能少的变换系数上。
DCT 量化:用像素值除以量化表对应值。由于量化表左上角的值较小、右下角的值较大,达到保持低频分量、抑制高频分量的目的。
注意:压缩不是在变换中,而是在量化变换系数时。量化是不可逆的,有损来源于量化操作。
zig-zag 扫描,对 8x8 的子图进行蛇形扫描,目的是:保证低频分量先出现,高频分量后出现,增加连续 0 的个数。
熵编码可以无损压缩信息,将出现概率大的数值用短码表示,出现概率小的数值用长码表示,编码后总长度小于编码前长度,达到无损压缩目的。JPEG 中常用的熵编码有两种:霍夫曼编码和算术编码。
霍夫曼编码:
回忆《数据与算法》课程,霍夫曼编码实际上就是一个构造霍夫曼树的过程,字符出现的概率就是霍夫曼树中叶子节点的权重。每一步都选取出现概率最小的两个字符,较小的放左边记为0,较大的放右边记为1,合成一个新节点,不断重复直到最后只剩下两个。
对于霍夫曼码,解码可以用简单的查表方式实现。特点:
- 是一种块(组)码,每个信源符号被映射成一组固定次序的码字;
- 是一种即时码,每个码字不需考虑后面的符号而解出;
- 是一种可唯一解码的码,任何符号串只有一种方式的解。
算术编码的特点:
- 算术编码是一种从整个符号序列出发,采用递推形式连续编码的方法。
- 在算术编码中,源符号和码字间的一一对应关系并不存在。
- 与霍夫曼方法不同,算术编码不需要将每个信源符号转换为整数个码字(即1次编1个符号)。与其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足 \(0.0\leqslant n<1.0\) 的小数 \(n\) .
编码是每一步都要把区间扩展为整个高度。编码过程中的位置计算方法:
新子区间起始位置 = 前子区间起始位置 + 当前符号区间左端 * 前子区间长度
新子区间结束位置 = 前子区间起始位置 + 当前符号区间右端 * 前子区间长度
通常,最后一个信源符号也用来作为符号序列结束的标志,即数据结束符。编完最后一个信源符号后,得到一个区间,该区间内任何一个实数都可以用来表示整个符号序列,最后需要转换为二进制表示,方法为“乘2取整”。
在算术编码中,只用到了加法和移位运算。
解码:根据编码时的信源符号集和概率分配表,及压缩后编码码字在的范围,可确定码字所对应的每一个信源符号。因为码字必在某个特定的区间,所以解码具有唯一性。编码器中需要添加一个专门的结束符,当译码器看到结束符时就停止译码。